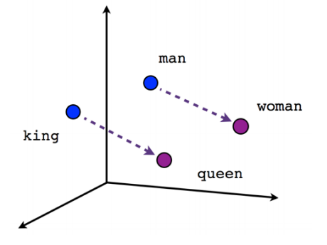
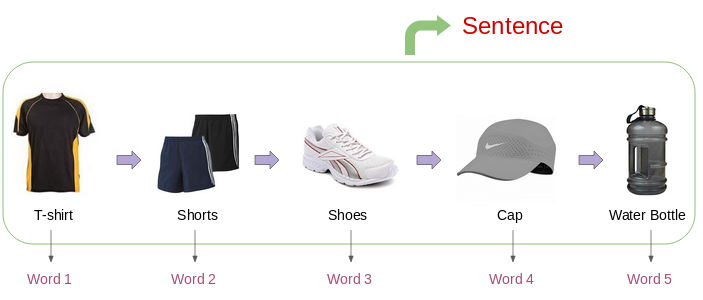
A comprehensive material on Word2Vec, a prediction-based word embeddings developed by Tomas Mikolov (Google). The explanation begins with the drawbacks of word embedding, such as one-hot vectors and count-based embedding. Word vectors produced by the prediction-based embedding have interesting properties that can capture the semantic meaning of a word. Therefore, we are interested in deep dive the Word2Vec in terms of its architecture, training optimization method, and how to do the hyperparameter tuning. We also tried to create Word2Vec embedding from scraped Wikipedia articles with the help of gensim and visualized it using elang - a Python package developed by Samuel Chan and me. We also present some other non-NLP use cases and developments from Word2Vec. At the end of this post, there are five multiple choice questions to test your understanding.
Apr 24, 2020