Product2Vec: Product Recommender System using Word2Vec
A Word2Vec implementation on simple product recommender system using Online Retail Dataset. We discuss how the classical use of Word2Vec can be applied to other non-NLP use cases. The trained Product2Vec model will be used to recommend new product based on last bought product and also based on multiple previous purchases. At the end of this post, there are two multiple choice questions to test your understanding.

- What is Product2Vec?
- Recommender Systems
- Import Libraries and Model
- Explore the Data
- Data Preparation
- Word2Vec Embeddings
- Start Recommending Products
- Test Your Understanding!
What is Product2Vec?
Can you guess the fundamental property of a natural language that Word2Vec exploits to create vector representations of text? It is the sequential nature of the text. Every sentence or phrase has a sequence of words. In the absence of this sequence, we would have a hard time understanding the text. Just try to interpret the sentence below:
prediction-based developed word a by Word2Vec is embeddings Tomas Mikolov.There is no sequence in this sentence. It becomes difficult for us to grasp it and that’s why the sequence of words is so important in any natural language. This very property can be applied to data other than text that has a sequential nature as well.
One such data is the purchases made by the consumers on E-commerce websites. Most of the time there is a pattern in the buying behavior of the consumers. For example, a person involved in sports-related activities might have an online buying pattern similar to this:
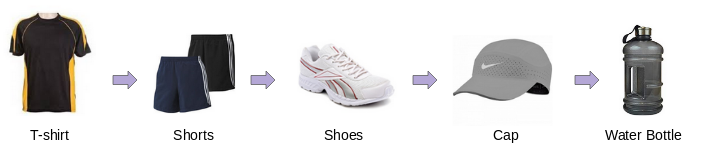
If we can represent each of these products by a vector, then we can easily find similar products. So, if a user is checking out a product online, then we can easily recommend him/her similar products by using the vector similarity score between the products.
But how do we get a vector representation of these products? Can we use the word2vec model to get these vectors?
We surely can! Just imagine the buying history of a consumer as a sentence and the products as its words:
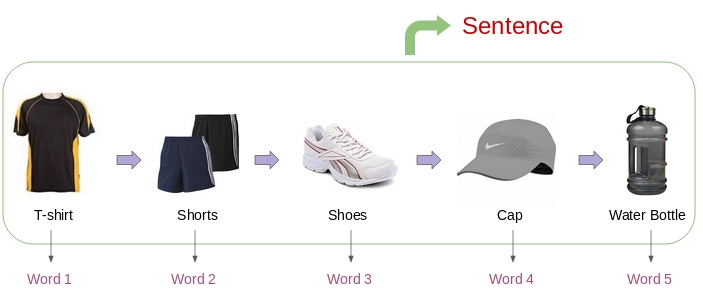
Now, let’s set up and understand our problem statement:
We are asked to create a system that automatically recommends a certain number of products to the consumers on an E-commerce website based on the past purchase behavior of the consumers.
Recommender Systems
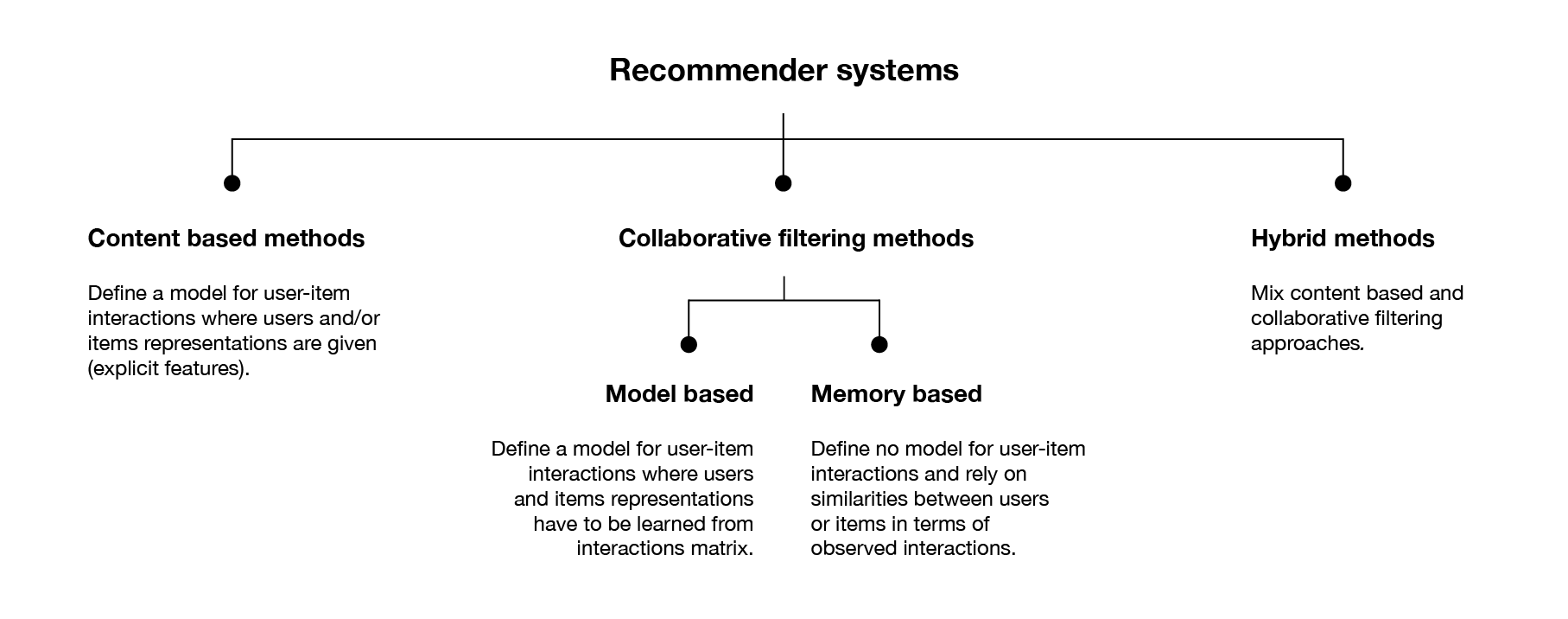
Collaborative:
(+) Require no information about users or items and, so can be used in many situations.
(+) More accurate recommendations, since new interactions recorded over time bring new information and make the system more effective.
(-) Cold start problem: Impossible to recommend items to new users or to recommend a new item to any users and many users or items have too few interactions to be efficiently handled.
Content-based:
(+) Suffer less from the cold start problem than collaborative approaches: new users or items can be described by their characteristics (content) and so relevant suggestions can be done for these new entities.
(-) Tend to over-specialize: it will recommend items similar to those already consumed, with a tendency of creating a "filter bubble".
We'll be using collaborative, memory-based method for our case study. Let's go:
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
# you can replace the id with id of file you want to access
model_id = "1-rFzYA2oNPm2F680L4FsjnkIpDzCDlwK"
downloaded = drive.CreateFile({'id': model_id})
downloaded.GetContentFile('recommender.model')
import pandas as pd
import numpy as np
# modeling
from sklearn.model_selection import train_test_split
from gensim.models import Word2Vec
# visualization
import matplotlib.pyplot as plt
%matplotlib inline
# other
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
pd.set_option('display.max_colwidth', -1)
Explore the Data
We are going to use an Online Retail Dataset that you can download from UCI Machine Learning.
url = 'https://github.com/tomytjandra/word2vec-embeddings/blob/master/dataset/Online%20Retail.xlsx?raw=true'
retail = pd.read_excel(url)
retail.head(10)
retail.info()
The dataset contains 541909 transactions. That is a pretty good number for us to build our model. Here is the description of the fields in this dataset:
-
InvoiceNo: Invoice number. a unique number assigned to each transaction StockCode: Product/item code. a unique number assigned to each distinct productDescription: Product name-
Quantity: The quantities of each product per transaction -
InvoiceDate: Invoice Date and time. The day and time when each transaction was generated -
UnitPrice: Price of each unit product CustomerID: Customer number. a unique number assigned to each customer-
Country: The country where each transaction was generated
retail["InvoiceDate"].is_monotonic_increasing
retail.isnull().sum()
Since we have sufficient data, we will drop all the rows with missing values.
retail.dropna(inplace=True)
retail.dtypes
retail["CustomerID"] = retail["CustomerID"].astype(int)
retail[["InvoiceNo", "StockCode", "Description", "CustomerID"]] = retail[["InvoiceNo", "StockCode", "Description", "CustomerID"]].astype(str)
retail["Country"] = retail["Country"].astype("category")
retail.dtypes
retail["Description"].values
Let's remove it:
retail["Description"] = retail["Description"].str.strip()
retail["Description"].values
customers = retail["CustomerID"].unique().tolist()
len(customers)
It is a good practice to set aside a small part of the dataset for validation purposes. Therefore, we will use the data of 95% of the customers to create word2vec embeddings. Let’s split the data.
customers_train, customers_val = train_test_split(customers, train_size=0.95, shuffle=True, random_state=123)
retail_train = retail[retail["CustomerID"].isin(customers_train)]
retail_val = retail[retail["CustomerID"].isin(customers_val)]
print("No. of Customers in Training Data:", len(customers_train))
print("Dim. of Purchases in Training Data:", retail_train.shape)
print("No. of Customers in Validation Data:", len(customers_val))
print("Dim. of Purchases in Validation Data:", retail_val.shape)
def purchasesList(df):
purchases_list = []
customers_list = df['CustomerID'].unique()
for customer in tqdm(customers_list):
customer_purchases_list = df[df["CustomerID"]
== customer]["StockCode"].tolist()
purchases_list.append(customer_purchases_list)
return purchases_list
purchases_train = purchasesList(retail_train)
purchases_val = purchasesList(retail_val)
from gensim.models.callbacks import CallbackAny2Vec
class Callback(CallbackAny2Vec):
def __init__(self):
self.epoch = 1
def on_epoch_end(self, model):
loss = model.get_latest_training_loss()
if self.epoch == 1:
print('Loss after epoch {}: {}'.format(self.epoch, loss))
else:
print('Loss after epoch {}: {}'.format(
self.epoch, loss - self.loss_previous_step))
self.epoch += 1
self.loss_previous_step = loss
model = Word2Vec(
size=100, # dimensionality of the word vectors
window=10, # max distance between context and target word
min_count=5, # frequency cut-off
sg=1, # using skip-gram
hs=0, # no hierarchical softmax (default)
negative=15, # negative sampling data
alpha=0.005, # learning rate
seed=123, # reproducibility
workers=1)
# STEP 2
model.build_vocab(purchases_train)
# STEP 3
callback = Callback()
model.train(purchases_train,
total_examples=model.corpus_count, # count of sentences
epochs=10, # number of iterations over the corpus
compute_loss=True, # to track model loss
callbacks=[callback])
Let’s check out the summary of our model:
model = Word2Vec.load("recommender.model")
print(model)
Our model has a vocabulary of 3196 unique products and their vectors of size 100 each. Next, we will extract the vectors of all the words in our vocabulary and store it in one place for easy access.
X = model[model.wv.vocab]
X.shape
Visualize Word2Vec
It is always quite helpful to visualize the embeddings that you have created. Over here, we have 100-dimensional embeddings. We can’t even visualize 4 dimensions let alone 100. What in the world can we do?
We are going to reduce the dimensions of the product embeddings from 100 to 2 by using various dimensionality reduction algorithm:
- Principal Component Analysis (PCA)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Uniform Manifold Approximation and Projection (UMAP)
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from umap import UMAP
X_pca = PCA(n_components=2).fit_transform(X)
X_tsne = TSNE(n_components=2, random_state=123).fit_transform(X)
X_umap = UMAP(n_components=2, random_state=123).fit_transform(X)
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
fig.patch.set_facecolor("white")
for ax, X_reduced, title in zip(axes, [X_pca, X_tsne, X_umap], ["PCA", "t-SNE", "UMAP"]):
ax.scatter(X_reduced[:, 0], X_reduced[:, 1], s=1)
ax.axis("off")
ax.set_title(title, fontsize=15)
plt.tight_layout()
fig.suptitle("WORD2VEC REDUCED DIMENSIONALITY",
size=25, y=1.075, fontweight="bold")
plt.show()

Start Recommending Products
Congratulations! We are finally ready with the word2vec embeddings for every product in our online retail dataset. Now, our next step is to suggest similar products for a certain product or a product’s vector.
Let’s first create a dictionary to easily map a product’s Description to its StockCode and vice versa.
products = retail[["StockCode", "Description"]]
# example of duplicates
products[products["StockCode"] == "22632"].drop_duplicates()
products.drop_duplicates(subset="StockCode", keep="last", inplace=True)
# create a dictionary for mapping
code_to_name = pd.Series(products["Description"].values, index=products["StockCode"]).to_dict()
name_to_code = pd.Series(products["StockCode"].values, index=products["Description"]).to_dict()
dict(list(code_to_name.items())[:20])
def similarProductsByVector(vec, n=10):
# extract most similar products for the input vector
similar_products = model.wv.similar_by_vector(vec, topn=n)
# extract name and similarity score of the similar products
product_list = []
for prod, sim in similar_products:
product_list.append((code_to_name[prod], sim))
return product_list
Let's try out our function by passing the StockCode "90019A" ('SILVER M.O.P ORBIT BRACELET')
code_to_name["90019A"]
similarProductsByVector(model["90019A"])
Identify last bought products for each CustomerID and recommend them 3 other similar products.
last_bought = retail_val.drop_duplicates(subset="CustomerID", keep="last")
last_bought.head()
recommendation_df = []
for idx, s in last_bought.iterrows():
temp_dict = {}
temp_dict["CustomerID"] = s["CustomerID"]
temp_dict["Last Bought Product"] = code_to_name[s["StockCode"]]
try:
temp_dict["Recommended Products"] = np.transpose(
similarProductsByVector(model[s["StockCode"]], n=4))[0][1:]
except KeyError:
continue
recommendation_df.append(temp_dict)
pd.DataFrame(recommendation_df).sample(5, random_state=123)
Cool! The results are pretty relevant and match well with the input product. However, this output is based on the vector of a single product only. What if we want recommend a user products based on the multiple purchases he or she has made in the past?
Case 2: Recommendation based on multiple purchases
One simple solution is to take average of all the vectors of the products he has bought so far and use this resultant vector to find similar products. For that we will use the function below that takes in a list of product ID's and gives out a 100 dimensional vector which is mean of vectors of the products in the input list.
def aggregateVectors(products):
product_vec = []
for i in products:
try:
product_vec.append(model[i])
except KeyError:
continue
return np.mean(product_vec, axis=0)
If you can recall, we have already created a separate list of purchase sequences for validation purpose. Now let's make use of that.
len(purchases_val[-1])
The length of the first list of products purchased by a user is 240. We will pass this products' sequence of the validation set to the function aggregate_vectors.
aggregateVectors(purchases_val[-1]).shape
Well, the function has returned an array of 100 dimensions. It means the function is working fine. Now we can use this result to get the most similar products. Let's do it.
similarProductsByVector(aggregateVectors(purchases_val[-1]))
As it turns out, our system has recommended products based on the entire purchase history of a user. Feel free to play the code, try to get product recommendation for more sequences from the validation set.
Test Your Understanding!
In this section, we will build a system to recommend similar products based on online transaction history which provided in Online Retail.xlsx. This dataset contains 541909 transactions and 8 columns as follow:
-
InvoiceNo: Invoice number. a unique number assigned to each transaction -
StockCode: Product/item code. a unique number assigned to each distinct product -
Description: Product name -
Quantity: The quantities of each product per transaction -
InvoiceDate: Invoice Date and time. The day and time when each transaction was generated -
UnitPrice: Price of each unit product -
CustomerID: Customer number. a unique number assigned to each customer -
Country: The country where each transaction was generated
After loading the dataset, make sure you have performed the following preprocessing step:
- Drop all the rows with missing value
- Convert each columns to its proper data type
- Remove leading and trailing whitespace on column
Description - Prepare a
code_to_nameand/orname_to_codedictionary mapping, assuming the product name used is the latest name by date
In order to get the same result, pre-trained model recommender.model is provided to you inside the folder models. The model has a vocabulary of 3196 unique products and size of the word vector is 100 dimensions. The parameters used to train the model are as follow:
- size = 100
- window = 10
- min_count = 5
- sg = 1
- hs = 0
- negative = 15
- alpha = 0.005
- seed = 123
- workers = 1
- epochs = 10
Please make sure to include the Callback class before loading the pre-trained model:
from gensim.models.callbacks import CallbackAny2Vec
class Callback(CallbackAny2Vec):
def __init__(self):
self.epoch = 1
def on_epoch_end(self, model):
loss = model.get_latest_training_loss()
if self.epoch == 1:
print('Loss after epoch {}: {}'.format(self.epoch, loss))
else:
print('Loss after epoch {}: {}'.format(self.epoch, loss - self.loss_previous_step))
self.epoch += 1
self.loss_previous_step = loss- Let's say we build a recommender system so that items that have at least a similarity score of 0.90 with previous transactions will appear on the "Product Recommendation" section of a website. Suppose there is a customer who only purchased one item, namely "BLUE PAISLEY TISSUE BOX". How many new products will appear on their "Product Recommendation" section?
- a. 9
- b. 10
- c. 11
- d. 12
If we use the system stated on previous question, the number of recommended products will be different for each customer. Suppose we change how our recommender system works. Now, for each customer, we want the model to recommend exactly 10 most similar products based on entire purchase history of a user.
First, you may need to find a list of purchased products for each customer:
purchased_product_for_each_customer = retail.groupby("...")["..."].apply(list)- Now, let's analyze customer with CustomerID "13160". Is there any product that they have purchased before, but the model recommends again? If yes, what is the product description?
- a. 15CM CHRISTMAS GLASS BALL 20 LIGHTS
- b. BLUE SPOT CERAMIC DRAWER KNOB
- c. DRAWER KNOB CERAMIC IVORY
- d. HEART WREATH DECORATION WITH BELL
- e. None of the top 10 recommended products have been purchased by the CustomerID "13160"